


Stable Diffusion web UI (chắc gọi là AUTOMATIC1111 hay A1111 đi) gần như là vua của mọi GUI cho user local rồi. Khổ cái, nó không có dễ tiếp cận (user-friendly). Và dễ làm người ta nản.
Sau khi training 2 buổi workshop cho chỗ làm, tôi thấy là A1111 này nó có thể hơi đáng sợ với họa sĩ / và các bạn mới làm quen. Trong phạm vi bài này, tôi sẽ (ráng) hướng dẫn bạn cách sử dụng GUI AUTOMATIC1111 - theo từng bước. Mình thoải mái đọc, cứ nhảy cóc qua mấy chỗ bạn chưa hứng thú rồi qua lại chỗ nào bạn cần cũng được.
Tôi cũng sẽ đưa các ví dụ để chứng minh tác dụng của một thông số (paramater) vì tôi tin rằng thực nghiệm cách duy nhất để làm mọi thứ rõ ràng / dễ hiểu.
Disclaimer: chắc là tôi sẽ lên bài hướng dẫn cài sau nhỉ (sẽ link ngược vào bài này) :(. Tạm thời, mọi người có thể xem chiếc Quick Start Guide free này
Text-to-image tab
Tab này mở lên thấy liền. Nhu cầu cơ bản khi xài SD mà: biến chữ thành hình.
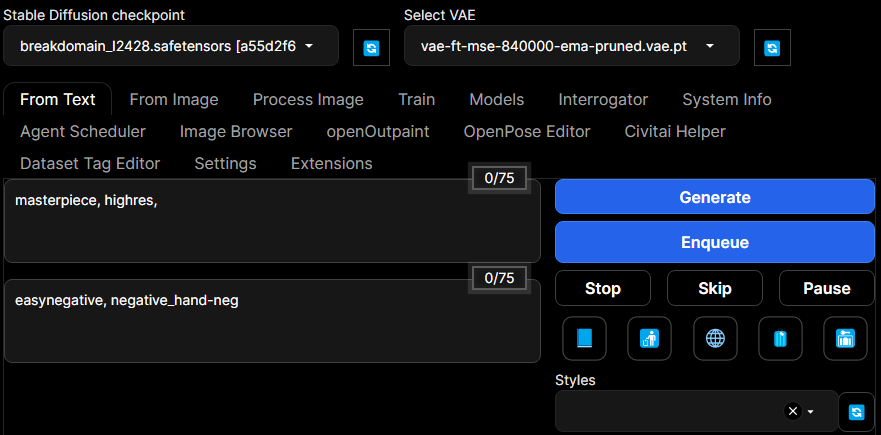
Các bước cơ bản
Lần đầu mở lên chắc mình sẽ chỉnh các cái settings này.

Stable Diffusion Checkpoint: Chọn model đi ạ. Thường khi mới cài, mình sẽ chỉ có SD v1.5.
Prompt: Mô tả hình ảnh bạn muốn tạo ra. Ví dụ:
a girl with blue hair.Width and height - chiều rộng và chiều cao: Kích thước của hình ảnh đầu ra. Bạn nên dùng ít nhất một bên thành 512 pixel (do SD1.5 được train từ các ảnh 512x512). Và nên tăng với tuyến tính chia hết cho 32.
Batch size: Số lượng hình ảnh được tạo mỗi lần. Tôi sẽ hay dùng batch size để test prompt, vì mỗi hình sẽ có 1 Seeds khác nhau (nếu Seeds = -1)
Xong rồi, bấm GENERATE thôi!
Cơ bản là vậy.
Các thông số trong A1111.

Stable Diffusion checkpoint là 1 menu sổ xuống, dùng để chọn checkpoint (tôi sẽ hay gọi chung là model hoặc SD model). Các models này cần được chép vào đây: /stable-diffusion-webui/models/Stable-diffusion.

Bên cạnh, nút màu xanh có chức năng refresh → khi bạn bỏ 1 model mới vào, refresh cái là thấy ngay.
Prompt: hãy gõ những thứ bạn muốn thấy ở đây. Đương nhiên, không có chiếc prompt nào là hoàn hảo rồi - bạn nên thử sai với nó.
Negative Prompt: hãy gõ những thứ bạn KHÔNG muốn thấy ở đây.
Có 2 format prompt:
Theo câu chữ:
a girl with blue hair.Đây là cách prompt thông dụng của MidjourneyTheo từ:
1girl, blue hair.Đây là cách prompt thông dụng của SD. Format này đến từ các trang web booru - các trang đăng hình ảnh được tag theo từ
Sampling method: là thuật toán cho quá trình denoising (có lướt qua trong bài này). Tôi hay xài DPM++ 2M Karras vì nó cân bằng tốt giữa tốc độ và chất lượng.
Chắc là bạn nên né các sampler có chữ ‘a’ (ancestral samplers). Nguyên nhân: tụi này không ổn định khi sử dụng ở sampling steps lớn.

Sampling steps: số bước cho quá trình denoising. Càng to càng tốt (và càng mất thời gian). 25 là lựa chọn tối ưu của tôi.

Width and height - chiều rộng và chiều cao: Kích thước của hình ảnh đầu ra. Bạn nên dùng ít nhất một bên thành 512 pixel (do SD1.5 được train từ các ảnh 512x512). Và nên tăng với tuyến tính chia hết cho 32.
Batch count: Số lần GENERATE.
Batch size: Số ẢNH trong 1 lần GENERATE.
Thông thường, tôi sẽ dùng batch count vì Batch size đòi hỏi 1 lượng vram lớn & dễ gây lỗi tràn vram.
CFG scale: thang Classifier Free Guidance là một tham số để quyết định SD model có nghe lời bạn không? Hiểu đơn giản, CFG có thể được coi là thang đo sáng tạo của SD. Số càng thấp thì SD tự do hơn & ngược lại.
TIPS:
CFG 2 – 6: Để SD tự do sáng tạo. Phù hợp với các prompt ngắn. Ở khoảng setting này, SD sẽ thường không nghe lời prompt.
CFG 7 – 10: Perfectly balanced, as all things should be... Cân bằng tốt giữa prompt và những thứ SD biết → Hãy hợp tác, AI!
CFG 10 – 15: dùng khi bạn tự tin với prompt sẽ cho ra thứ bạn muốn → Trust me, AI!
CFG 16 – 20: tôi không xài, nhưng bạn có thể thử. CFG ở khoảng này = LÀM KHÔNG SD? HAY TÔI ĐẬP LUÔN CÁI PC NÀY?
CFG >20: THÔI BỎ ĐI

Seed
Seed là thông số quyết định noise - độ nhiễu (ngẫu nhiên) ban đầu mà tôi đã để cập trong bài trước. Về nguyên lý, seed có thể coi như là thông số quyết định bố cục của ảnh cuối. Mỗi hình ảnh được SD tạo ra đều có 1 số seed định danh. AUTOMATIC1111 mặc định sẽ để số này là -1 (ngẫu nhiên).
khi chép prompt, nhớ thay seed.
Seed là 1 thông số khá hay, đặc biệt hữu ích khi cần điều chỉnh prompt. Ví dụ với prompt: sfw, highres, 1girl, blue hair,

Tôi thích bố cục của chiếc ảnh này, nhưng tôi thích mắt màu nâu. thì tôi sẽ giữ lại seed & điều chỉnh prompt.

Chép cái seed này vào seed setting. Hoặc dùng nút xanh lá này để tái sử dụng seed trước đó.

Ok, giờ thêm brown eyes vào thì: sfw, highres, 1girl, blue hair, brown eyes,

Bạn để ý, bố cục hình không giống 100% được. Nguyên nhân là: trong prompt mới lúc này, đã có vài từ khóa đủ mạnh để thay đổi bố cục ảnh
Giờ, ấn xúc xắc để trả về -1 thôi.

Extra seed
Bật Extra thì sẽ thấy Extra seed menu. trong này có:

Variation seed: giá trị seed bổ sung
Variation strength: Độ tương quan giữa Seed và Variation seed.
Variation strength = 0 thì Variation seed = Seed (giá trị của Variation Seed được quyết định bởi Seed)
Variation strength = 1 thì Seed = Variation seed. (giá trị của Seed được quyết định bởi Variation seed)
Hơi loạn đúng không? Ví dụ đi; hình này tôi generate với prompt sfw, highres, 1girl, magic


Giờ, tôi muốn blend 2 hình này với nhau thì sẽ setting như vầy:

Như hình dưới, tác động của Variation strength lên 2 Seed phía trên là:

Restore faces
Restore faces dùng một mô hình bổ sung - mô hình này được đào tạo để khôi phục các khiếm khuyết trên khuôn mặt. Ví dụ:

Lúc xài Restore Face, mình cần chọn model nào để dùng. Setting này nằm trong Settings > Face restoration

Tôi hay để CodeFormer làm mặc định. Chỉnh CodeFormer weight = 0 để model chạy full tính năng.
Tuy nhiên, Restore faces KHÔNG NÊN dùng khi xài chung với LORA.
Tiling
Tiling dùng để tạo ra pattern kiểu này:

Hires. fix.
High-resolution fix sẽ upscale hình lên bằng 1 upscaler tùy biến. Vì SD 1.5 được train từ hình 512x512 (v2 thì train từ 768x768), nên là nếu gen hình với độ phân giải cao hơn thì hơi bất tiện nếu không dùng Hires. fix.
Ơ anh chủ blog, tôi thích để 1024x1536 thì sao?
Ok, chiều. Đây là hình 1024x1024, prompt: sfw, 1girl

Cũng là prompt với Seed này, nhưng có Hires. fix

Nếu gen hình với prompt
1girlmà nhận ra nhiều girls thì là do mình đang không để độ phân giải ở 512Chốt: nên gen hình có ít nhất là 512 ở dài hoặc rộng, rồi scale up lên.
Khi xài Hires. fix, mình lưu ý:
Upscaler: chọn 1 chiếc upscaler để xài
Các tùy chọn upscale có chữ Latent sẽ scale hình trong latent space. Về nguyên lý, tụi này hoạt động gần giống image-to-image.
Hires steps: Áp dụng cho các Latent upscalers. Nó là số bước upscale sau khi xử lý hình ảnh. Vd: Hình của bạn đang có 30 Sampling steps & Hires. steps = 0 → SD sẽ sampling 30 steps để ra hình gốc, và chạy tiếp 30 steps upscale. Tương tự, nếu Hires. steps = 10 thì SD sẽ sampling 30 steps để ra hình gốc, và chạy tiếp 10 steps upscale.
Denoising strength: Áp dụng cho các Latent upscalers. Tương tự Denoising strength ở image-to-image. Thông số này quyết định số lượng Noise bỏ thêm vào, sao 30 steps sampling như ví dụ ở trên.
Ok, xem tí ví dụ về denoise strength khúc này nha:


Vì lý do nào đó mà người viết cũng không biết, denoise strength phải lớn hơn 0,5 để ra đượng hình ảnh sắc nét. Và rõ là, ở denoise càng cao thì hình càng khác.
Lý do mà mọi người thấy cái hình nó rõ →mờ → rõ lúc Hires. fix là: hình generate bình thường → thả noise để upscale → upscale. Khúc thả noise chính là lúc mờ.
Lợi thế của việc sử dụng Latent upscalers là nó sẽ KHÔNG tạo ra thêm các chi tiết nhỏ (như ESRGAN). Hạn chế là nó sẽ thay đổi bố cục hình ảnh ở một mức độ nào đó, tùy thuộc vào giá trị của denoise strength.
Upscale by: kiểm soát hình ảnh được upscale mấy lần. Ví dụ hình trên, tôi chọn Upscale by = 2; thì hình gốc từ 512 x 768 pixel thành 1024 x 1536 pixel.
Ngoài ra, mình cũng chỉnh được các giá trị của “resize width to” và “resize height to” để tạo ra kích thước hình ảnh mới.
Mấy cái nút chi chít ở dưới nút Generate

Từ trái qua:
Đọc và phân bổ prompt: cá luôn là nhiều bạn copy prompt và copy từng parameters vào từng ô. ĐỪNG LÀM VẬY! Copy cả prompt vào Possitive Prompt rồi ấn nút này thôi. Thử xem
Thùng rác: là xóa hết prompt, làm lại
cuộc đờitừ đầu.Nút Model: để hiện Extra Networks (có thể là hypernetworks, embeddings, LoRA)
Load style: Xả các style đã lưu ở nút 5 lên prompt
Save style: Lưu prompt - cả positive prompt and the negative prompt
Mấy cái nút chi chít ở dưới file hình

Tương tự, từ trái qua
Open folder: mở thư mục lưu ảnh của SD (hehe, A1111 có cơ chế tự lưu ảnh nha).
Save: Lưu ảnh thủ công. Bấm cái là hiện ra bảng download.
Zip: Nén batch hình vừa tạo thành file zip rồi tải.
Send to img2img: gửi hình qua tab img2img.
Send to inpainting: gửi hình qua tab inpainting tab - thuộc tab img2img.
Send to extras: gửi hình qua tab Extras.
Chắc bài sau, tôi nói về các tab img2img, extras… này nhé. Cheer!
Thầy ơi lúc nào thì có hướng dẫn cài ạ :D?