
Stable Diffusion chạy kiểu gì?
Hiểu đơn giản cách mà Stable Diffusion biến mấy chữ thành một hình ảnh ngoạn mục.

Thật ra thì để xài Stable Diffusion (SD) mình không cần phải hiểu hiểu cách thức hoạt động của nó. Tuy nhiên, việc hiểu SD giúp mình dễ điều khiển các tham số - parameters như Seed, Sampler, Steps, CFG Scale hoặc Denoising strength để tạo ra hình ảnh chất lượng.
Trong bài viết này, chúng ta sẽ hiểu một cách khái quát cách SD hoạt động bên ở các phiên bản 1.x và cách nó có thể tạo ra hình ảnh chỉ bằng một câu từ đơn giản.
Disclaimer: bài này đúng vào lúc viết, và có thể không đúng vào lúc khác :(
TL; DR
Các bước chính khi SD tạo ra hình ảnh:
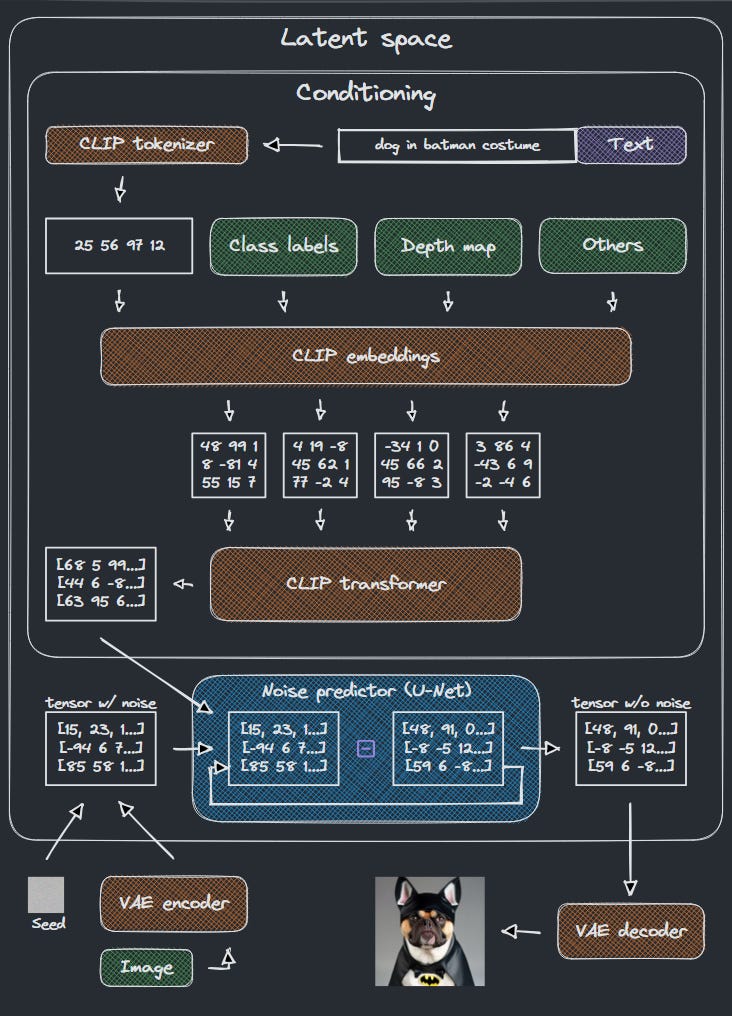
Một tensor với latent noise được tạo ra dựa trên một seed cố định hoặc ngẫu nhiên. Trong trường hợp Inpainting, ảnh gốc được sử dụng làm cơ sở đầu vào.
Các điều kiện (chẳng hạn như text, depth map hoặc label) được chuyển đổi thành embeddings vector lưu trữ dữ liệu trong nhiều dimensions.
Các vector này đi qua CLIP transformer model - chịu trách nhiệm tính toán mối quan hệ giữa các embeddings và các dữ liệu của chúng bằng cross-attention technique (tạm dịch: kỹ thuật chú ý chéo).
Noise predictor (U-Net) bắt đầu quá trình denoising (tạm dịch: khử nhiễu) bằng cách sử dụng kết quả của CLIP transformer để định hướng. Quá trình này sử dụng kỹ thuật sampling (tạm dịch: lấy mẫu) và lặp lại nhiều lần theo số bước (steps) đã chỉ định.
Trong quá trình này, noise được tạo ra bởi thuật toán sampling và bị trừ dần khỏi tensor ban đầu. Sau mỗi step, noise tenor được tạo ra sẽ là input bước tiếp theo → cho đến khi tất cả các steps được hoàn thành. Noise scheduler kiểm soát số lượng noise trừ ra ở mỗi bước sao cho nó không tuyến tính.
Khi quá trình denoising kết thúc, tensor rời latent space thông qua VAE decoder - chịu trách nhiệm chuyển đổi nó thành hình ảnh.
Cách mà 1 chiếc model chạy:
Trong machine learning, có kha khá các loại generative models (mô hình có khả năng tạo dữ liệu, trong trường hợp này là hình ảnh). Một loại gọi là diffusion models - tạm dịch là các mô hình khuếch tán - vì chúng mô phỏng hành vi khuếch tán phân tử. Khuếch tán phân tử là hiện tượng mà tất cả chúng ta hay gặp khi mở máy lạnh, hoặc đổ đá vào ly beer - khi các hạt có xu hướng di chuyển và lan rộng.
Forward Diffusion
Stable Diffusion được train từ hàng trăm nghìn bức ảnh (có thể là chôm chỉa) được lấy từ Internet → và rồi thêm Gaussian Noise vào hình ảnh qua nhiều bước → cho đến khi hình ảnh trở thành 1 đống “bụi nhiễu” - noise. Quá trình này được gọi là Forward Diffusion (vì nó tiến về phía trước).

Reverse Diffusion
Rồi, khi mà mình xài SD và bảo nó là: Gen cho tôi 1 con chó mặc đồ batman - điều kỳ diệu được gọi là Reverse Diffusion (tạm dịch là khuếch tán ngược) xảy ra. Và như tên gọi, Reverse Diffusion là một quá trình đảo ngược của Forward Diffusion.
Thuật ngữ inference hay được sử dụng trong khi nói về những gì một model học được trong quá trình training. Trong trường hợp của SD, thuật ngữ này có thể được sử dụng cho quá trình Reverse Diffusion.
Bước đầu tiên: SD sẽ tạo một hình ảnh 512x512 pixel toàn noise - rất là vô tri. Cơ mà để tạo ra cái hình toàn là noise này, chúng ta cũng có thể sửa đổi một tham số được gọi là Seeds, có giá trị mặc định là -1 (ngẫu nhiên). Ví dụ: nếu chúng ta sử dụng Seeds = 4376845645 thì số lượng và cách phân bổ noise sẽ luôn là như nhau - dù cho chúng ta có bấm generate trăm nghìn lần; bởi vì seed đã được định danh.
Như vậy, kết quả của một hình ảnh có thể được sao chép nếu chúng ta biết hạt giống của nó.
Bước tiếp theo: để SD biến chiếc hình toàn là noise này một hình ảnh đầy noise thành 1 con chó mặc đồ batman, SD cần biết được số lượng noise trong ảnh. SD làm được việc này nhờ được trained với convolutional neural network. Hệ thống này gọi là U-Net (hoặc denoising U-Net), mặc dù trong SD, nó được gọi là noise predictor.
Việc đào tạo cho SD hệ thống này bao gồm: sử dụng các hình ảnh của quá trình Forward Diffusion + đào tạo khả năng học hỏi. Ví dụ: tôi bảo rằng ảnh đầu tiên có 0% noise, ảnh giữa 50% và ảnh cuối cùng 100%… chắc chắn bạn sẽ có thể phân biệt được mức độ noise hiện có trong một bức ảnh mới vì bạn đã hiểu pattern rồi.

Sampling
Ở lúc này, SD đã có: 1 hình toàn noise + số lượng noise trong hình. Đây là lúc quá trình Sampling (tạm dịch: lấy mẫu) bắt đầu.
Noise predictor ước tính mức độ noise trong ảnh → thuật toán Sampling tạo ra một hình ảnh có lượng noise đó → khử noise để cho ra kết quả. Toàn bộ quá trình này được lặp lại theo số lần chỉ định bởi parameter Steps (aka. sampling steps).

Một khúc quan trọng khác của thuật toán sampling là noise scheduler - có chức năng quản lý lượng noise cần loại bỏ ở mỗi bước. Noise reduction tuyến tính (i.e giảm noise cùng số lượng ở mỗi bước), sẽ tạo ra những thay đổi đột ngột trên hình ảnh. Noise scheduler với các bước giảm phù hợp có thể loại bỏ một lượng lớn noise ban đầu để sử lý nhanh hơn, sau đó chỉ cần loại bỏ ít nhiễu hơn để điều chỉnh chi tiết nhỏ trong hình ảnh.


Cơ mà… làm thế nào SD biết rằng có một 1 con chó mặc đồ batman ở bên dưới đám noise đó?
Câu trả lời là nó không biết :(. Tới khúc này, chúng ta đã hiểu cách SD tạo ra một hình ảnh vô điều kiện - unconditioned image. Kết quả có thể là 1 con chó không mặc đồ batman hoặc 1 con mèo hoặc NSFW vì MÌNH CHƯA BỎ PROMPT VÀO.
Conditioning - điều kiện hóa
Welp, cái thú vị thú vị của SD không phải là tạo ra hình ảnh ngẫu nhiên.
Ở trên, mình nói về noise predictor được train từ: hình ảnh và độ nhiễu. Do đó, chúng ta có thể điều khiển noise predictor theo ý mình bằng cách hướng dẫn nó. Thay vì hỏi “Có bao nhiêu noise trong hình vậy chú SD?”; ta hỏi “Mức độ noise trong bức ảnh chụp 1 con chó mặc đồ batman là bao nhiêu?” để điều hiện hóa - conditioning - và cho ra hình ảnh cuối.
Prompting không phải là cách duy nhất để tạo điều kiện cho noise predictor. Và mình sẽ cùng nhau đi qua vài cách thông dụng bên dưới.
Text-to-Image (t2i)
Chuyển từ chữ sang hình là chức năng cơ bản nhất của SD rồi. Quá trình này gọi là Text-to-Image bao gồm các module như sau
Tokenizer
Vì máy tính sẽ KHÔNG hiểu chữ cái, nên nhiệm vụ đầu tiên sẽ là sử dụng tokenizer để chuyển từng chữ thành một số gọi là ký hiệu (token).
Với SD, việc này thực hiện được nhờ CLIP model (Contrastive Language-Image Pre-Training). Model này được tạo ra bời OpenAI - dùng để mô tả chi tiết một hình ảnh bằng chữ cái, mặc dù SD chỉ sử dụng CLIP built-in tokenizer cho tác vụ này.

Chính là nút clip intergorate ở màn hình image-to-image trong giao diện A1111

Lưu ý: Tokenizer KHÔNG phải lúc nào cũng chuyển đổi từng từ thành token. Các từ ghép/ký tự/khoảng trắng cũng có ảnh hưởng đến số lượng token mà SD nhận được.
Hôm trước tôi có nghe đâu đó bảo là Giới hạn chữ của 1 chiếc prompt là 77. Thật ra, giới hạn này tồn tại do tokens được lưu trữ trong một vector có kích thước tối đa là 77 tokens (1x77). Như vậy, giới hạn được đề cập đúng ra là giới hạn của tokens chứ không phải là giới hạn chữ của prompt. Sure, đúng là sau 77 tokens thì phần còn lại của prompt sẽ bị cắt. Nhưng, với prompting techniques (như BREAK) có thể phân tách & nối các chunks 77 tokens đủ để cover cho cả prompt (nếu prompt vượt hơn giới hạn 77 tokens).
Tokenizer là 1 process chỉ xảy ra ở t2i.
Embedding
Tưởng tượng 1 tẹo: tôi cho bạn 10 hình & bạn phải phân loại tụi nó trên một đồ thị hai chiều với X = lượng tóc & Y = tuổi tác. Kết quả sẽ trông như này:

Cái này gọi là embeddings - đây là cách phân loại các thuật ngữ (terms) và khái niệm (concepts) bằng cách lưu trữ dữ liệu trong vectors. Stable Diffusion dùng một phiên bản của CLIP là ViT-L/14 - với vectors có 768 chiều (dimensions). Khó để biết các chiều này có thông tin gì (vì mình không có dữ liệu đào tạo của Stable Diffusion), nhưng bạn cứ hình dung là một chiều được dùng để lưu trữ màu sắc, một chiều khác là kích thước của các vật thể, lại thêm 1 chiều về kết cấu, 1 chiều khác về biểu cảm khuôn mặt, 1 chiều về độ sáng, 1 chiều về khoảng cách không gian giữa các vật thể... BAM, 768 dimensions.
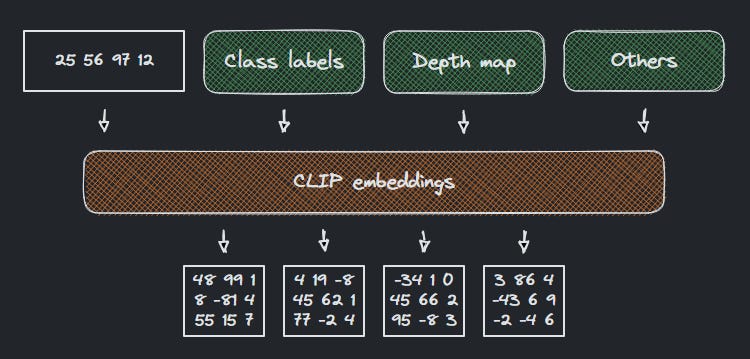
Embedding được dùng với vì khi các terms đã được lưu trong dimensions, chiếc model SD có thể tính toán khoảng cách giữa chúng.

Ví dụ dễ hiểu (và thực tế - tụi nó phức tạp hơn nhiều): Bằng kỹ thuật này, các nhóm dimensions chứa khái niệm về quần áo sẽ gần hơn nhóm dimensions chứa các khái niệm về người, thay vì các nhóm dimensions chứa khái niệm về cửa hoặc bàn ghế.
Mỗi token lại chứa 768 dimensions. Nghĩa là, nếu chúng ta xài prompt car, token car sẽ được chuyển đổi thành một vector 768 chiều. Khi điều này được thực hiện với tất cả tokens trong prompt, chúng tôi sẽ có 1 Embedding với kích thước 1x77x768.
Bằng cách này, chúng ta có thể đo khoảng cách của tất cả các dimensions của tất cả tokens.
Transformer
Đây là bước cuối cùng của conditioning. Khúc này, embedding được xử lý bằng CLIP transformer model (gọi tắt là transformer).
Kiến trúc mạng Neural Network này bao gồm nhiều lớp và chịu trách nhiệm điều chỉnh & hướng dẫn noise predictor theo từng bước hướng bội để đạt được hình ảnh đại diện cho thông tin của embedding.
Ở phần t2i, embedding được gọi là Text embedding (obviously), nhưng CLIP transformer model có thể nhận được embeddings từ các điều kiện khác bên dưới.
Transformer có khả năng self-attention (tạm dịch: tự chú ý) khi tất cả các embeddings có cùng trọng lượng (weight) và ảnh hưởng đến kết quả hình ảnh như nhau. Thêm nữa, SD lại có cơ chế cross-attention (tạm dịch: chú ý chéo). Kỹ thuật này bao gồm tính toán các mối quan hệ phụ thuộc giữa các embeddings và tạo ra một tensor với kết quả. Lúc này là lúc mà khoảng cách giữa các dimentions (ở trên) được tham chiếu.

Ví dụ: với prompt red wall with a wooden door, nếu chỉ dùng kiến trúc self-attention → ta có thể tạo ra một bức tường gỗ với một cánh cửa màu đỏ (chớ không phải một bức tường đỏ với một cánh cửa gỗ).
Nhờ cross-attention, transformer tính toán khoảng cách giữa gỗ/cửa và giữa gỗ/tường và biết rằng lực chọn đầu tiên có nhiều khả năng/ở gần nhau hơn.
Ví dụ: khi tôi bảo bạn nghĩ về 1 chiếc xe màu đỏ; khả năng cao là bạn nghĩ về Ferrari chứ không phải Toyota Supra
Kỹ thuật này được gọi là attention (tạm dịch: sự chú ý) vì nó bắt chước quá trình nhận thức mà chúng ta trải nghiệm trong đời thường. Nhờ thông tin từ CLIP transformer model, noise predictor được dẫn dường chỉ lối để tiến gần hơn tới hình ảnh chứa cấu trúc có thể xảy ra nhất với conditioning (ở đây là prompt).
Class labels và thang CFG
Điều kiện này rất quan trọng vì nó giúp transformer bằng cách sử dụng các nhãn/tag/label.
Một bộ an external classifier (CG - classifier guidance - tạm dịch: phân loại bên ngoài) được sử dụng khi train SD. Đây là một mô hình chịu trách nhiệm gán nhãn (tag) cho các hình ảnh inputs. Như vậy, ảnh chụp chó sẽ có nhãn animal và dogs, trong khi ảnh chụp mèo sẽ có nhãn animal và cats (và nhiều nhãn khác, như mèo tam thể - calico cats).
Khi sử dụng giá trị cao ở thang CG, chúng ta yêu cầu transformer tách các nhãn không giống nhau và tập trung vào các nhãn giống nhau. Mặt khác, với giá trị thấp, như thể các nhãn được đưa lại gần hơn → khi yêu cầu hình con mèo, chúng ta có thể nhận được ảnh của bất kỳ con vật nào khác (hoặc bất kỳ nhãn nào khác gần đó).
Để tránh phải sử dụng external classifier model và giảm bớt khó khăn trong quá trình training, quá trình này đã được cải tiến bằng một kỹ thuật gọi là classifier-free guidance (CFG trong A1111) - hướng dẫn không cần bộ phân loại. Có nghĩa là giờ mình không cần classifier model để gắn nhãn cho hình ảnh. Tức là trong lcu1 train, SD dùng hình ảnh để tự động phân loại nhãn.
Bằng việc điều chỉnh tham số CFG (CFG scale), chúng ta có thể phân định ít nhiều ranh giới của các nhãn mà chúng ta muốn sử dụng để tạo ra hình ảnh. Nói nôm na, CFG là thang đo độ sáng tạo của SD so với prompt của bạn.
Theo kinh nghiệm của tôi, giá trị tối ưu là từ 5.5 đến 7.5. CFG ảnh hưởng trực tiếp với Sampling Steps. Khi xài ít steps (10 - 30), thì CFG phải từ 4-7. Khi xài >50 steps thì CFG có thể lên 13+. Rule of thumb là CFG = 6,7,8 là good
Image-to-Image
Image-to-Image (i2i) là khi mình dùng 1 chiếu hình để làm conditioning cho kết quả.
Ví dụ: để tôi vẽ 1 chiếc nhà → bỏ vào SD với prompt a realistic photograph of a wooden house with a red door in the middle of the forest → SD sẽ coi đây là 2 conditionings & cho ra kết quả bên dưới
Sao thần kỳ vậy? Welp, nhớ lại bước 1 ở trên không? SD sẽ tạo ra một hình ảnh toàn noise ở bước 1?

Như vậy, thay vì SD tạo ra 1 bức ảnh toàn noise - giờ tôi bỏ cho SD luôn một lượng noise. Với tham số Denoising strength, tôi có thể kiểm soát mức độ noise mà tôi muốn thêm vào. Giá trị 0 → không có noise & giá trị 1 → mình cho noise đầy ảnh như cái cách mà t2i làm. Lý tưởng nhất là giá trị ở giữa 0 với 1, đuơng nhiên con số này phụ thuộc vào mức độ tự do mà mình muốn SD nghe theo.

Inpainting
Inpainting là kỹ thuật giúp mình thay đổi nội dung của hình ảnh - có thể coi đây là img2img cho 1 vùng nhất định trong ảnh.

Outpainting
Tương tự Outpainting là kỹ thuật giúp mình phát triển thêm nội dung của hình ảnh - bằng cách tạo ra khu vực chưa từng tồn tại của hình.

Other
ControlNet là một mạng neural network sử dụng một loạt các mô hình để tạo điều kiện cho đầu ra theo nhiều cách khác nhau: depth map, openpose, canny map…



The latent space - Không gian Latent
Nãy giờ, mình đang làm việc trên các pixel của hình ảnh - được gọi là image space (tạm dịch: không gian hình ảnh). Hình 512x512 pixel và màu RGB tương ứng với 1 không gian kích thước 786432 = 3x512x512, thứ mà bạn không thể chạy trên máy local.
Giải pháp cho vấn đề này là sử dụng mô hình latent diffusion model (tạm dịch: khuếch tán tiềm ẩn - LDM). Thay vì làm việc trên một không gian lớn như vậy, LDM sẽ nén không gian này thành một latent space nhỏ hơn 64 lần (3x64x64).
“Ô mà bạn ơi, làm thế nào có thể nén thông tin của một hình ảnh thành một thứ nhỏ hơn 64 lần mà không làm mất chi tiết?”
Đó là vì chúng ta thực sự không cần đầy đủ các thông tin khi generate hình ảnh. Một người bình thường lên ảnh sẽ có mặt, hai mắt, mũi, miệng, v.v. → Thay vì lưu trữ tất cả thông tin của một hình ảnh, LDM lưu các thông tin phổ biến/chung - có khả năng thể hiện hình ảnh một cách hiệu quả nhất. Thông tin này được lưu trữ dưới dạng số trong một tensor có kích thước 3x64x64.
Variational autoencoder (tạm dịch: bộ mã hóa tự động biến đổi - VAE) là một loại mạng neural network có khả năng chuyển đổi từ hình ảnh thành một tensor trong latent space (encoder) hoặc từ một tensor thành hình ảnh (decoder).
SD cho phép bạn lựa VAE nào sẽ sử dụng. Tùy tình huống, một số VAE mang lại kết quả tốt hơn, vì có kha khá các số thông tin bị mất latent space và VAE chịu trách nhiệm khôi phục các thông tin đó.

VAE decoder: xảy ra ở t2i, khi SD có kết quả cuối cùng trong latent space, tensor đi qua bộ giải mã VAE decoder để trở thành hình ảnh 512x512 pixel. Như vậy, nếu ảnh bị bệt màu, thường là do bạn đang không có VAE.
Stable Diffusion và tương lai của nó
Nãy giờ tôi chỉ đang nói về SD 1.x. Khác biệt giữa SD 1.4 & 1.5 là thời lượng trainning → 1.5 cho ra ảnh chất lượng tốt hơn 1.4.
SD 2.x lại có chất lượng tốt hơn nữa. SD 1.x sử dụng model ViT-L/14 từ Open AI trong khi SD 2.x sử dụng model OpenCLIP từ LAION. Mô hình này là phiên bản lớn hơn của ViT-L/14 và đã được đào tạo bằng hình ảnh copyright-free. Kích cỡ hình lớn hơn - 768x768 pixel (thay vì 512x512 pixel của 1.x) cho ra các hình ảnh với chất lượng/độ phân giải cao hơn.
Copyright-free giúp cộng đồng dễ thở hơn về các vấn đề bản quyền khi sử dụng SD. Tuy nhiên, trong một số trường hợp, kết quả của SD 2.x có chất lượng kém hơn so với 1.x khi tạo hình ảnh theo nét vẽ của các họa sĩ nổi tiếng hoặc khuôn mặt của người diễn viên/celebs. SD 2.0 cũng chặn NSFW; và bị hạn chế ở 2.1.
Nên là, >80% các model thịnh hành đều đang được fine-tune / tinh chỉnh trên SD 1.5, thay vì 2.x
Phiên bản SDXL 1.0 mới sẽ được phát hành vào giữa tháng 7 năm 2023; chia làm 2 bản: based model và refiner. Cả hai đều sử dụng hình ảnh inputs có độ phân giải lên tới 1024x1024 với các tỷ lệ khung hình khác nhau. Based model dùng 2 mô hình để mã hóa văn bản (text encoding): OpenCLIP ViT/G từ LAION và ViT-L/ từ Open AI. Mô hình refiner chỉ sử dụng OpenCLIP và được đào tạo để tinh chỉnh các chi tiết nhỏ → lợi thế tốt hơn ở i2i. Tôi xài bản leak 0.9 và thấy là cả hai mô hình đều cho ra chất lượng cao hơn nhiều so với các phiên bản SD trước.
Coi thêm so sánh của SDXL và các phiên bản trước ở đây
Cám ơn ông, bài viết của ông rất có giá trị, nhưng tôi xin góp ý một chút.
Bài viết của ông thực sự rất hay, cũng rất dễ hiểu, nhưng nó chỉ dễ hiểu cho các bạn đã có những kiến thức nền tảng cơ bản về SD. Còn đối với các bạn là người mới hoàn toàn, chưa hề biết một chút khái niệm gì về AI thì sẽ hoàn toàn mù tịt về các khái niệm, các thuật ngữ mà ông đưa ra
Để giải quyết vấn đề này thì tôi có hai hướng. Cách thứ nhất là ông cắm link một vài bài viết cung cấp kiến thức cơ bản về SD vào đầu bài của ông. Cách này thì phổ thông rồi, không bàn
Cách thứ hai, đó là ông sẽ trừu tượng hóa các khái niệm thành những thứ quen thuộc trong cuộc sống. Cách này thì nó sẽ giúp người đọc không cần có kiến thức chuyên sâu cũng có thể hiểu một cách đại khái quá trình hoạt động của SD.
Cám ơn đóng góp của anh